
Опубліковано: 2026-06-08
Word Frequency Analysis: How to Find Overused Words
Find the words you repeat too often with a word frequency counter online. Learn the 0.5% tic threshold, what's normal vs. overused, and how to fix it.

The fastest way to find the words you overuse is to stop trusting your own ear. You can't hear your own verbal tics — that's what makes them tics. Word frequency analysis counts every unique word, ranks them by how often they appear, and shows each as a percentage of your total, so the repetition you can't feel becomes a number you can't miss.
Here's the threshold that matters: any ordinary content word sitting above 0.5% of your total word count is worth a hard look. In a 1,000-word essay, that's just five appearances. Below is how to run the analysis, read it correctly, and fix what it surfaces.
What "Overused" Actually Means (The Numbers)
Not all repetition is bad. English is wildly top-heavy by design — a handful of function words make up a huge share of any text. This is Zipf's law: the most common word in a corpus appears roughly twice as often as the second most common, three times as often as the third, and so on. In natural English, "the" alone is about 7% of all words. That's not a problem; it's grammar.
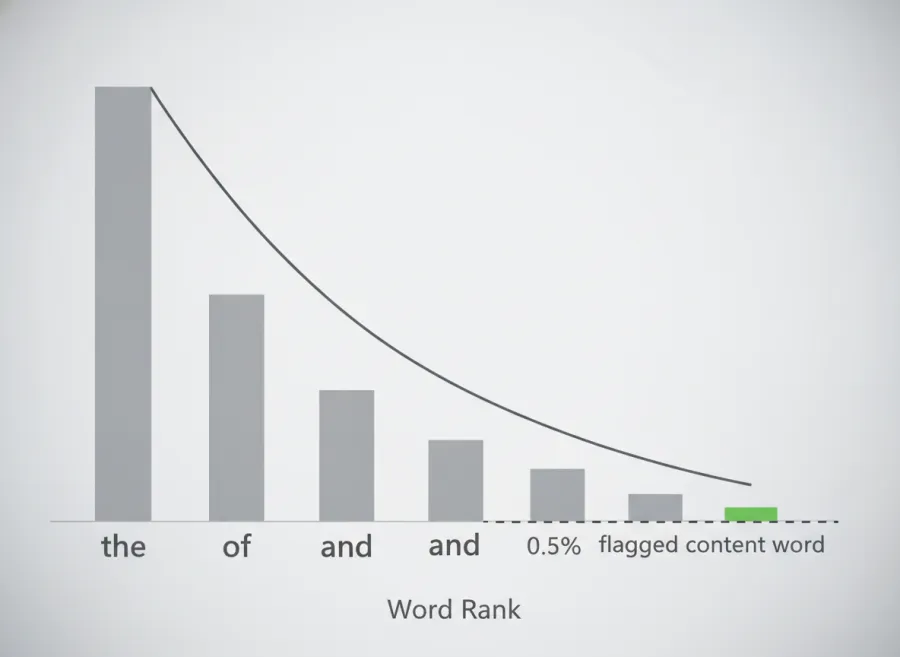
The shape above is the whole story in one curve. The first few bars — the function words — tower over everything, then the line plunges and flattens into a long tail. Your content words live in that tail. When one of them climbs up out of the tail and crosses the 0.5% line, it's standing somewhere it wasn't meant to be. That's the visual signature of a verbal tic.
So the trick is knowing which numbers are normal and which are a red flag.
| Word type | Typical frequency | Verdict |
|---|---|---|
| Function words (the, of, and, to) | 2–7% | Normal — this is Zipf's law, leave it alone |
| Your topic keyword / character name | 1–3% | Expected — context-dependent, usually fine |
| Generic content word (just, really, things) | > 0.5% | Likely a tic — investigate |
| Filler adverb (very, actually, basically) | any cluster | Cut on sight — these add wordiness, not meaning |
The reason 0.5% is the line: at that rate a reader starts to notice the word, even subconsciously. It's the point where repetition crosses from invisible to grating. A frequency counter that shows percentages — not just raw counts — lets you apply this threshold regardless of document length.
To run your own numbers, paste your draft into our Word Frequency Counter — it runs entirely in your browser's V8 engine, your text never touches a server — and it'll rank every word with live counts and percentages in one pass.
How to Read the Results Without Fooling Yourself
A ranking is only useful if you interpret it correctly. Three settings change what you see, and the defaults are tuned for exactly this task.
1. Keep "Exclude common words" on. The counter filters a built-in English stop-word list — the, and, of, is, pronouns, and ~80 other high-frequency function words. Without this filter, your top 10 is just grammar and you learn nothing. With it on, the first real signal — your most-repeated content word — jumps to the top of the list.
2. Set the minimum word length to 4. This skips most filler in one move (it, was, but) while keeping the words that carry meaning. Bump it to 5 or 6 if your top results are still cluttered with short connective words.
3. Read the percentage column, not the count. A word appearing 40 times sounds alarming until you realize the document is 30,000 words long — that's 0.13%, perfectly fine. The percentage is calculated against your total word count, including the stop words you filtered out of the display, so it's an honest denominator. Sort by percentage and start from the top.
What you're scanning for: a generic verb or adjective punching above 0.5%. "Showed," "looked," "important," "great," "thing" — these are the usual suspects. When one of them outranks words that actually carry your argument, you've found a tic.
The Words Writers Repeat Without Knowing
Some patterns show up in nearly every draft. Run the analysis on enough text and you start to predict them.
- Crutch verbs: make, get, go, put, take. They're so flexible they sneak in everywhere. "Make a decision," "get an understanding," "take a look" — each is a stronger single verb hiding behind a weak one.
- Throat-clearing adverbs: very, really, actually, basically, literally. These cluster. If "very" appears 15 times, you don't have an emphasis problem — you have 15 places where a precise word would beat "very + vague word."
- Hedge words: just, quite, somewhat, perhaps, maybe. One or two soften a sentence; a dozen make your writing sound unsure of itself.
- Echo nouns: thing, stuff, way, area, aspect. Placeholder nouns you meant to replace and forgot.
This is exactly the raw material for cutting length. Once you've identified an overused crutch verb, the techniques in How to Reduce Word Count turn each hit into a tighter, stronger sentence — replacing "she made a decision" with "she decided" both removes the tic and drops the word count.
Frequency Analysis vs. Find & Replace — Use Both
Finding the overused word is step one. Fixing it is step two, and they need different tools.
The frequency counter is your diagnosis — it tells you looked appears 23 times in a 4,000-word chapter (0.58%, over the line). It does not, and should not, blindly swap them. Replacing all 23 with the same synonym just trades one tic for another.
For the fix, jump to Find & Replace, which highlights every occurrence in context so you can decide case by case — some "looked"s become "studied," some "glanced," some get cut entirely. It supports full regex with the u flag for Unicode text, so you can match whole words only (/\blooked\b/giu) and skip partial matches inside other words. Diagnose with frequency, treat with find-and-replace. Neither does the other's job well.
One footgun worth knowing if you adapt these patterns: in JavaScript, \b is ASCII-only, even with the u flag. It works perfectly for looked, but /\bдивився\b/giu or /\bschön\b/giu can misfire next to Unicode punctuation or non-breaking spaces, because the engine doesn't treat Cyrillic or umlaut letters as "word characters" at the boundary. For solid non-English matching, anchor on the surrounding whitespace or punctuation instead — e.g. lookarounds like /(?<=^|[\s,.])looked(?=$|[\s,.])/giu — rather than trusting \b.
This diagnose-then-treat loop is the backbone of a chapter audit. If you're editing fiction, the chapter length guide walks through pairing per-chapter word counts with frequency analysis to catch tics that cluster in specific scenes — action sequences are notorious for stacking the same three verbs.
A Length-Aware Repetition Cheat Sheet
The 0.5% threshold is constant, but it's easier to act on as a raw count. Here's what "overused" looks like at common document lengths.
| Document | 0.5% threshold | What it means |
|---|---|---|
| 500-word essay | ~3 hits | Tight — repeating a content word 3× is already noticeable |
| 1,000-word blog post | ~5 hits | The classic case; 5+ of any non-keyword word is a tic |
| 2,500-word chapter | ~13 hits | Verbs are the usual offenders here |
| 10,000-word short story | ~50 hits | Character names get a pass; generic verbs don't |
| 80,000-word manuscript | ~400 hits | Run chapter-by-chapter — book-wide totals hide local clusters |
The manuscript row holds the most important caveat: a word can look fine across an entire novel and still be jammed into a single chapter. Book-wide frequency averages out local repetition. That's why editors run the analysis per chapter, not per book — a verb at 0.1% across 80,000 words might be at 1.5% in the one scene where you lost control of it.
Why the Tokenizer Matters
Most free frequency counters split text on spaces — text.split(' '). It's the junior approach, and it breaks the moment your writing contains anything interesting. "Don't" becomes one token; "mother-in-law" becomes one token instead of being counted sensibly; an em-dash—like this—glues two words together; and any non-English script returns nonsense.
The Word Frequency Counter tokenizes with Intl.Segmenter, the W3C-standard word boundary detector built into every modern browser (it's what Chrome's own spell-checker uses). It correctly handles contractions, hyphenated compounds, accented characters, and even Chinese or Japanese, which have no spaces between words at all. If your frequency data is wrong because the tokenizer is naïve, every percentage above is wrong too — accuracy starts at the segmentation step.
For the same reason, when you want a precise total word count to sanity-check your percentages against, the Word Counter uses the identical engine, so the two tools always agree.
FAQ
What is word frequency analysis? It's the process of counting how many times each unique word appears in a text and ranking them most-to-least common. The goal is to surface unconscious repetition — the crutch verbs and filler adverbs you lean on without realizing. Showing each word as a percentage of the total separates deliberate keywords from accidental tics.
How do I find overused words in my writing? Paste the text into a word frequency counter, keep the stop-word filter on, and set a minimum word length of 4. Read the top 30 by percentage. Any content word above ~0.5% of your total is a candidate — about 5 hits per 1,000 words. Ignore your topic keyword and character names; target the generic verbs and adjectives that rank unexpectedly high.
What percentage counts as overusing a word? Function words (the, of, and) live at 2–7% and that's normal — it's just how English distributes. Ordinary content words start to feel repetitive above roughly 0.5%, and anything past 1% in a non-keyword role is almost certainly a tic. Fiction gets one exception: a protagonist's name routinely sits at 1–3% without bothering anyone.
Is a word frequency counter the same as keyword density? Same math, opposite goal. Keyword density is SEO — you want a target phrase to appear often enough to signal relevance without tripping spam filters. Frequency analysis is editing — you're hunting repetition to cut. In one you're chasing a number up; in the other you're bringing it down.
Why does the counter ignore words like "the" and "and"? Those are stop words, and they top every list by sheer grammar, drowning out real signal. The tool filters a built-in English stop-word list by default so your most-repeated content word rises to the top instead. Toggle the filter off if you specifically want to study function-word distribution.
Does word frequency analysis work in other languages?
Yes — tokenization runs on Intl.Segmenter, which handles accented characters, apostrophes, hyphenated words, and space-less scripts like Chinese correctly, unlike text.split(' '). The built-in stop-word list is English, though, so for other languages turn the stop-word filter off and read the raw ranking.