
Опубліковано: 2026-05-12
Як рахувати слова в JavaScript: 5 методів порівняно
Від наївного split() до Intl.Segmenter — 5 методів підрахунку слів у JavaScript за точністю, підтримкою Unicode та крайовими випадками. Який везти в прод.
text.split(' ').length. Кожен джуніор-JS-розробник це відправляв у прод. І воно неправильне щонайменше у три різні способи.
Це повний розбір п'яти підходів до того, як рахувати слова в JavaScript — що кожен реально робить під капотом, де він ламається і який варто взяти. Спойлер: це Intl.Segmenter.
Чому рахувати слова важче, ніж здається
Текст відчувається простим. Слова ж розділені пробілами, так? Окрім випадків:
- Подвійні пробіли між реченнями (
hello world→ split дає 3 токени, а не 2) - Нерозривні пробіли (
- Табуляції й переноси рядка — валідні пробільні символи, які
split(' ')ігнорує - CJK-текст — у китайській, японській, корейській узагалі немає пробілів між словами
- Емодзі — сімейне емодзі (
👨👩👧👦) це 1 видимий символ, але 11 кодових одиниць UTF-16, 6 кодових точок Unicode і 1 кластер графем - Скорочення й дефіси —
don't,state-of-the-art— це 1 слово чи 2?
Більшість багів підрахунку невидимі, поки на твій застосунок не натрапить неангломовний користувач.
П'ять методів
Метод 1: text.split(' ').length — наївний split
function countWords(text) {
return text.split(' ').length;
}
Це перше, що люди пишуть. І воно неправильне одразу.
countWords('hello world') // → 3 (extra empty string token)
countWords('hello\tworld') // → 1 (tab not counted as separator)
countWords('') // → 1 (empty string gives [''], not [])
Вердикт: не відправляй це в прод. Ніколи.
Метод 2: text.trim().split(/\s+/).filter(Boolean).length — залатаний split
function countWords(text) {
return text.trim().split(/\s+/).filter(Boolean).length;
}
Значно краще. /\s+/ матчить будь-яку послідовність пробільних символів — пробіли, табуляції, переноси рядка, повернення каретки. trim() опрацьовує пробіли на початку й у кінці. filter(Boolean) відкидає порожні рядки.
countWords('hello world') // → 2 ✓
countWords('hello\tworld') // → 2 ✓
countWords('') // → 0 ✓
countWords('héllo wörld') // → 2 ✓ (accent characters preserved)
Де ламається: CJK-текст. '你好世界'.trim().split(/\s+/) повертає ['你好世界'] — один токен, а не чотири слова. Також рахує токени лише з пунктуації: якщо на вході -- --, отримаєш 2 фантомні «слова».
Вердикт: годиться для суто англійських інструментів. Зламано для глобальної аудиторії.
Метод 3: (text.match(/\b\w+\b/g) || []).length — класична регулярка
function countWords(text) {
return (text.match(/\b\w+\b/g) || []).length;
}
Ти бачитимеш це всюди на Stack Overflow. Проблема в \w.
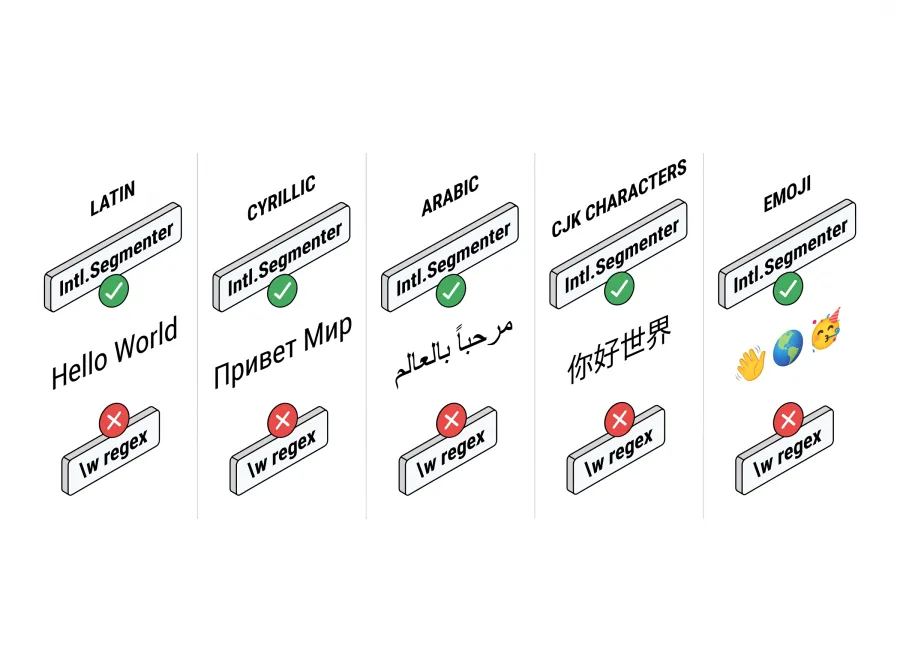
У JavaScript \w — це [A-Za-z0-9_]. Оце весь набір. Кожен символ поза ASCII — кирилиця (привет), арабська (مرحبا), грецька (γεια), корейська (안녕) — невидимий для цієї регулярки. Запасний || [] тебе видає: без нього .match() повертає null за відсутності збігів, а це був би весь рядок для нелатинського тексту.
countWords('hello world') // → 2 ✓
countWords('привет мир') // → 0 ✗ (Cyrillic not matched)
countWords('héllo') // → 1, but counts 'h llo' internally → actually still 1 but accented chars may be excluded
Вердикт: прийнятно для дев-інструментів, що обробляють лише ASCII. Тихий провал для всього іншого.
Метод 4: (text.match(/\p{L}+/gu) || []).length — Unicode Property Escapes
function countWords(text) {
return (text.match(/\p{L}+/gu) || []).length;
}
\p{L} — це Unicode Property Escape, що означає «будь-яка літера Unicode». Прапор u обов'язковий — без нього V8 кидає SyntaxError, бо \p невалідний у не-Unicode режимі. Прапор g знаходить усі збіги глобально.
countWords('hello world') // → 2 ✓
countWords('привет мир') // → 2 ✓ (Cyrillic works)
countWords('héllo wörld') // → 2 ✓ (accented chars work)
countWords('你好 世界') // → 2 ✓ (space-separated CJK)
countWords('你好世界') // → 1 ✗ (no spaces, counts as one match)
Числа й окрема пунктуація виключаються автоматично, що зазвичай і потрібно.
Вердикт: чудово для латиниці, кирилиці, арабської, грецької, єврейської та CJK із пробілами. Усе ще не вміє сегментувати CJK без пробілів.
Метод 5: Intl.Segmenter — правильна відповідь
function countWords(text) {
const segmenter = new Intl.Segmenter('und', { granularity: 'word' });
let count = 0;
for (const { isWordLike } of segmenter.segment(text)) {
if (isWordLike) count++;
}
return count;
}
Intl.Segmenter — це API інтернаціоналізації W3C, доступний у всіх сучасних JavaScript-рантаймах (Baseline 2023). Передавай 'und' як локаль для незалежної від локалі сегментації або свою конкретну локаль ('zh', 'ja') для правил із урахуванням мови.
Прапорець isWordLike — ось ключ: він true для справжніх слів і false для пробілів, пунктуації й роздільників. Жодної фільтрації не треба.
countWords('hello world') // → 2 ✓
countWords('привет мир') // → 2 ✓
countWords('你好世界') // → 2 ✓ (你好 = hello, 世界 = world — dictionary segmentation)
countWords("don't stop") // → 2 ✓ (contraction = 1 word)
countWords('state-of-the-art') // → 4 ✓ (hyphenated = 4 words, matches editorial convention)
countWords('') // → 0 ✓
Вердикт: використовуй це. Саме це браузери застосовують усередині для перевірки орфографії й виділення тексту.
Примітка щодо Node.js: на Node.js 16+ зі стандартним складанням
full-icuIntl.Segmenterпрацює з коробки. Якщо ти на старішій версії чи на складанніsmall-icu(поширене в деяких Docker-образах), можеш отриматиTypeError: Intl.Segmenter is not a constructor. Полагодь це, встановивши пакетfull-icuі передавши--icu-data-dirпід час старту — або просто оновись до Node 18+, де повні дані ICU вшито за замовчуванням.
Таблиця порівняння точності
| Метод | Англійська | Діакритика | Кирилиця/Арабська | CJK (без пробілів) | Порожній рядок | Скорочення |
|---|---|---|---|---|---|---|
split(' ') | ✗ (подвійні пробіли) | ✓ | ✓ | ✓ | ✗ (повертає 1) | ✓ |
trim().split(/\s+/) | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
/\b\w+\b/g | ✓ | ✗ | ✗ | ✗ | ✓ | ✓ |
/\p{L}+/gu | ✓ | ✓ | ✓ | ✗ | ✓ | ✓ |
Intl.Segmenter | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
Рядок Intl.Segmenter — єдиний, де всі галочки.
Міркування щодо продуктивності
Для документа на 1000 слів усі п'ять методів мізерні — менш ніж 1 мс на будь-якій сучасній машині. Різниця проявляється на масштабі.
На 100 000 слів (повний рукопис роману):
- Регулярні методи (
/\p{L}+/gu) виконуються за ~20–40 мс — досить швидко для підрахунку в реальному часі на подіяхinput Intl.Segmenterвиконується за ~80–120 мс — усе ще менше за 100 мс, але вже близько до порога для плавного UI на 60fps
Емпіричне правило: для вхідних даних понад 50 000 слів запускай лічильник у Web Worker. Передай текст через postMessage, запусти сегментатор у контексті воркера й відправ результат назад. Головний потік лишається незаблокованим.
// word-count.worker.js
self.onmessage = ({ data: text }) => {
const segmenter = new Intl.Segmenter('und', { granularity: 'word' });
let count = 0;
for (const { isWordLike } of segmenter.segment(text)) {
if (isWordLike) count++;
}
self.postMessage(count);
};
Якщо хочеш звірити свою реалізацію з еталонною, встав текст у наш Лічильник слів — працює на 100% у твоєму браузері, нуль даних на жоден сервер — і порівняй лічбу зі своєї функції з тим, що показує він.
Коли який метод використовувати
| Сценарій | Рекомендований метод |
|---|---|
| Швидкий скрипт лише для англійської | trim().split(/\s+/) |
| Продакшен-застосунок, багатомовний | /\p{L}+/gu |
| Продакшен-застосунок + підтримка CJK | Intl.Segmenter |
| Node.js CLI, будь-яка мова | Intl.Segmenter (Node ≥16) |
| Легасі-браузери (IE, старий Safari) | trim().split(/\s+/) + примітка про поліфіл |
Крайові випадки з реального світу для тестів
Перш ніж відправляти лічильник слів у прод, прожени його на цих входах. Якщо бодай якийсь дає неочікуваний результат — у твоєму методі є баг:
// 1. Multiple whitespace types
"hello\t\nworld" // expect: 2
// 2. Non-breaking space (pasted from Word)
"hello world" // expect: 2
// 3. Zero-width space (pasted from web)
"helloworld" // expect: 1 or 2 (debatable, document your choice)
// 4. Pure punctuation
"... --- ???" // expect: 0
// 5. Numbers only
"123 456" // expect: 0 (if counting "words" = letters only)
// expect: 2 (if counting tokens)
// 6. Mixed script
"hello мир" // expect: 2
// 7. Emoji in text
"Great job 🎉" // expect: 2 (emoji is not a word)
// 8. Hyphenated compound
"state-of-the-art design" // Intl.Segmenter → 5; /\p{L}+/gu → 5; split → 2
Випадок із дефісом — той, що збиває людей найбільше. Універсальної «правильної» відповіді немає — англійські стайлгайди не згодні між собою. Обери поведінку, задокументуй її й будь послідовним.
Що використовує Лічильник слів на цьому сайті
Лічильник слів на editlyapp.com використовує Intl.Segmenter із /\p{L}+/gu як запасний варіант для середовищ, де API ще недоступний. Сегментатор працює на головному потоці для документів до 50 000 слів і перемикається на Web Worker для більших входів — утримуючи відгук UI під 16 мс незалежно від довжини рукопису.
Це той самий підхід, що описаний у статті Оцінка читабельності простими словами, де сегментація речень використовує Intl.Segmenter із granularity: 'sentence', щоб точно живити формулу Flesch-Kincaid.
Якщо ти будуєш текстовий інструмент на регулярках і треба протестувати патерни на реальному вмісті, інструмент Пошук і заміна на цьому сайті підтримує повні регулярки з прапором u — зручно для валідації твоїх патернів /\p{L}+/gu, перш ніж заводити їх у застосунок.
Остаточна реалізація
Ось готова до продакшену версія, що опрацьовує кожен випадок вище:
/**
* Count words in any language using Intl.Segmenter.
* Falls back to Unicode regex for environments without Segmenter support.
*/
function countWords(text) {
if (!text || !text.trim()) return 0;
if (typeof Intl !== 'undefined' && Intl.Segmenter) {
const segmenter = new Intl.Segmenter('und', { granularity: 'word' });
let count = 0;
for (const { isWordLike } of segmenter.segment(text)) {
if (isWordLike) count++;
}
return count;
}
// Fallback: Unicode Property Escapes (all modern browsers, no IE)
return (text.match(/\p{L}+/gu) || []).length;
}
Зверни увагу на дві речі. По-перше, ранній return на порожньому вході чи лише з пробілів — Intl.Segmenter на порожньому рядку повертає нуль сегментів, але гард тут явний. По-друге, перевірка наявності фічі Intl.Segmenter замість try/catch — чистіше й дешевше.
FAQ
Який найточніший спосіб рахувати слова в JavaScript?
Intl.Segmenter із granularity: 'word' — найточніший. Це стандартний API W3C, вбудований у V8, який коректно опрацьовує CJK, арабську, тайську (без меж за пробілами), кластери емодзі, слова через дефіс і скорочення. Для більшості суто англійських випадків /\p{L}+/gu із прапором u — надійна, простіша альтернатива.
Чому text.split(' ').length повертає неправильну лічбу?
Три причини. По-перше, він рахує порожні рядки, коли в тексті є кілька пробілів поспіль — 'hello world'.split(' ') повертає ['hello', '', 'world'], довжина 3, а не 2. По-друге, він не бачить табуляцій (\t), переносів рядка (\n) і нерозривних пробілів (U+00A0). По-третє, він рахує пробіли на початку/в кінці як фантомні слова, поки ти не зробиш trim().
Чи працює /\b\w+\b/g для неанглійського тексту?
Ні. \w — це [A-Za-z0-9_]. Кожен кириличний, арабський, грецький, єврейський, корейський, китайський і японський символ дає нуль збігів. Якщо ти будуєш бодай щось для неамериканської аудиторії, ця регулярка мовчки видає неправильну лічбу. Натомість використовуй /\p{L}+/gu із прапором u.
Що таке Intl.Segmenter і чи безпечно його використовувати в проді?
Intl.Segmenter — це API інтернаціоналізації W3C, вбудований у V8 (Chrome/Node.js), SpiderMonkey (Firefox) і JavaScriptCore (Safari). Він досяг статусу Baseline 2023 — усі три головні браузерні рушії його підтримують. Для Node.js доступний починаючи з v16.0.0. Можеш використовувати без поліфілу в будь-якому сучасному середовищі.
Як рахувати слова в Nuxt чи React застосунку з великими текстами?
Для текстів до ~50 000 слів будь-який метод працює досить швидко на головному потоці. Для більших входів — рукописів, вставлених книжок, масової обробки — винеси у Web Worker, щоб не фризити UI. Передавай сирий рядок через postMessage і запускай сегментатор у контексті воркера.
Скорочення рахуються як одне слово чи два?
В англійській прозі скорочення (don't, it's, you're) мають рахуватися як одне слово — це збігається з тим, як рахують редактори, вчителі й видавці. Intl.Segmenter із granularity: 'word' коректно повертає don't як один сегмент-слово.
Чому мій лічильник не збігається з Google Docs чи Microsoft Word?
Google Docs і Microsoft Word використовують пропрієтарні алгоритми токенізації, що публічно не задокументовані. Google Docs зазвичай виключає виноски й рахує складні слова через дефіс як одне слово. Word за замовчуванням враховує виноски й може ділити слова через дефіс інакше залежно від встановленого мовного пакета. Intl.Segmenter із isWordLike дає найближче наближення до галузевого редакторського підрахунку — і, на відміну від обох платформ, його поведінка повністю передбачувана, бо специфікація W3C публічна.
Як рахувати слова, не рахуючи числа чи токени лише з пунктуації?
З Intl.Segmenter перевіряй segment.isWordLike === true — API автоматично позначає пунктуацію й пробіли як несловесні сегменти. З /\p{L}+/gu за визначенням матчаться лише послідовності літер, тож числа й окрема пунктуація виключаються.
Глибший погляд на те, як патерни регулярок поводяться на реальному тексті, — у Гайді з регулярних виразів: пошук і заміна, що покриває групи захоплення, квантифікатори й lookahead — усе, що треба, щоб будувати надійні патерни обробки тексту поза підрахунком слів.