
Опубліковано: 2026-05-17
Як видалити дублікати рядків у VS Code (і онлайн)
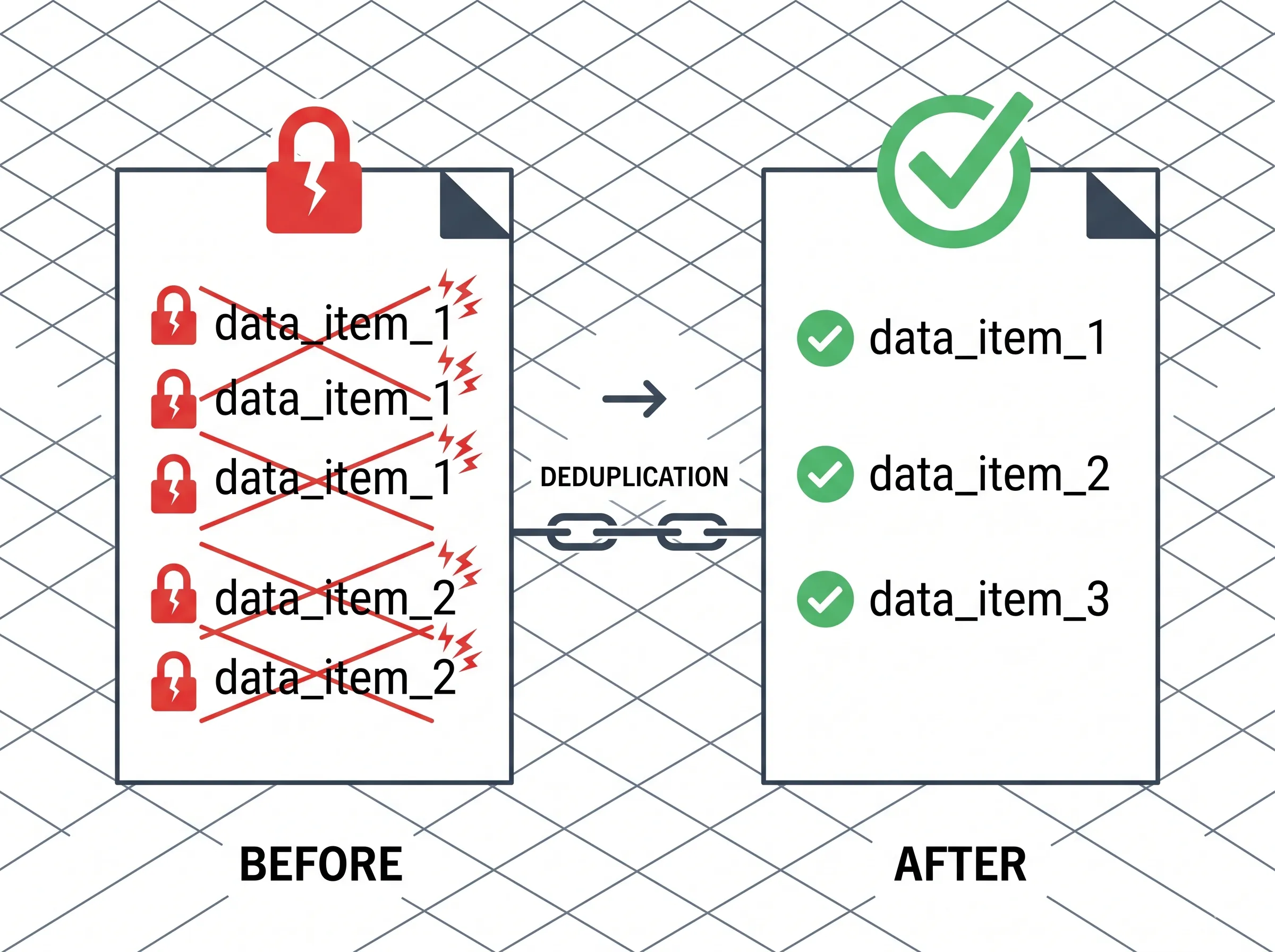
У VS Code немає вбудованої команди дедуплікації. Ось 5 методів — обхід через сортування, awk-однорядковик, PowerShell, розширення й браузерний інструмент — з порівнянням порядку, швидкості й крайових випадків.
VS Code вміє багато речей. Видалення дублікатів рядків — не одна з них, принаймні не рідно. У Command Palette немає пункту «Remove Duplicates». Ніколи й не було.
Якщо ти доігрався до роздутого конфіг-файлу, CSV з повтореними рядками чи лог-дампу, напханого однаковими записами, ти вже шукав команду, якої не існує. Ось пʼять методів, що реально працюють, упорядкованих за тим, коли по який тягнутися.
Метод 1: обхід через сортування (VS Code, без розширень)
Це підхід із нульовими залежностями. Він працює, коли порядок рядків не має значення — наприклад, записи .gitignore, списки залежностей, файли ключових слів.
- Відкрий файл у VS Code
- Виділи все:
Ctrl+A(Windows/Linux) абоCmd+A(macOS) - Відкрий Command Palette:
Ctrl+Shift+P/Cmd+Shift+P - Запусти Sort Lines Ascending (A→Z)
- Дублікати рядків тепер сусідні — вони візуально очевидні
- Для маленьких файлів: видали послідовні повтори вручну
Обмеження очевидне: це знищує твоє початкове впорядкування. Для .gitignore чи списку імпортів це нормально. Для лог-файлу, де важлива послідовність, це непрохідний варіант.
Метод 2: однорядковик у терміналі (порядок збережено)
Для файлів, де порядок важить, це правильний підхід. Одна команда, без редактора.
macOS / Linux — зберігає порядок:
awk '!seen[$0]++' input.txt > output.txt
Це елегантно. seen[$0] — це асоціативний масив із ключем за повним вмістом рядка. ! інвертує істинність — рядок друкується лише першого разу, коли трапляється. Кожен наступний дублікат тихо відкидається. Порядок збережено, нуль конфігурації.
Примітка щодо macOS: системний
awkна macOS — це One True Awk, який може поводитися неочікувано зі складним Unicode-вмістом чи закінченнями рядків\r\nу стилі Windows. Якщо маєш справу з тим чи іншим, встанови GNU awk через Homebrew (brew install gawk) і підставgawkзамістьawkу команді вище.
macOS / Linux — найшвидше, але порядок НЕ збережено:
sort -u input.txt > output.txt
sort -u — це реалізація на C із зовнішнім сортуванням злиттям. Для файлів понад 500 000 рядків вона помітно швидша за awk. Але вона впорядковує вивід за абеткою, що робить її неправильною для структурованих даних.
Windows PowerShell — зберігає порядок:
Get-Content .\input.txt | Select-Object -Unique | Set-Content .\output.txt
Select-Object -Unique лишає перше входження й відкидає наступні збіги. За поведінкою еквівалентно підходу з awk.
Метод 3: regex Find & Replace (лише послідовні дублікати)
Якщо твої дублікати йдуть поспіль, інструмент Пошук і заміна може зловити їх регуляркою. Цей патерн матчить послідовно повторені рядки:
^(.+)(\r?\n\1)+$
Замінити на: $1
У VS Code: Ctrl+H → увімкни regex (Alt+R) → встав патерн → заміни все. VS Code автоматично опрацьовує межі ^ і $ рядок за рядком у Find & Replace — окремий multiline-прапор не потрібен, але режим Regex має бути ввімкнений, інакше символи ^, $ і \n трактуються як літерали. Щоб ловити послідовні дублікати, що різняться регістром (наприклад, Error і error поспіль), вимкни Match Case (Alt+C) у панелі пошуку — інлайнові прапори (?i) у regex-рушії VS Code поводяться непослідовно між версіями й менш надійні за перемикач у панелі.
Критичне обмеження: це видаляє лише послідовні дублікати. Якщо line A зʼявляється на рядку 1 і рядку 100 з іншим вмістом поміж, ця регулярка проґавить його повністю. Підходи awk і sort -u сканують увесь файл незалежно від позиції.
Щодо синтаксису регулярок, груп захоплення й патернів lookahead — гайд з регулярних виразів: пошук і заміна покриває все, що треба, щоб адаптувати цей патерн до складніших сценаріїв.
Метод 4: розширення VS Code
Розширення «Remove Duplicate Lines» від Pauls0n додає рівно одну команду в Command Palette. Встанови його, виділи свій текст (чи весь файл), запусти команду — готово.
Компроміс: воно вимагає інсталяції й надання довіри. На машині, яку ти не контролюєш — корпоративний ноутбук, VPS, робоча станція колеги — це не завжди варіант. Для повторюваного робочого процесу на власній машині це найчистіше рідне рішення для VS Code.
Метод 5: браузерний інструмент (без налаштування, будь-яка машина)
Встав свій текст у наш інструмент Видалити дублікати — працює цілком у V8-рушії твого браузера, нуль даних кудись передається — і отримаєш миттєвий результат із контролами, яких методи в терміналі не дають:
- Лишити перше чи лишити останнє входження (sort -u лишає «перше» довільно, на основі порядку сортування; тут це явно)
- Перемикач без урахування регістру (без гімнастики з
tolower()в awk) - Обрізати пробіли перед порівнянням (щоб
" hello "і"hello"згорнулися в один рядок) - Прев'ю «до/після» зі зведенням за кількістю рядків
Для разової задачі чищення на будь-якій машині це найшвидший шлях. Відкрий браузер, встав, скопіюй результат.
Порівняння методів
| Метод | Зберігає порядок | Без урахування регістру | Обрізає пробіли | Лише послідовні | Налаштування |
|---|---|---|---|---|---|
| Обхід через сортування у VS Code | Ні | Ні | Ні | Ні | Жодного |
awk '!seen[$0]++' | Так | Додай tolower() | gsub(/^[ \t]+|[ \t]+$/, "") | Ні | Unix-термінал |
sort -u | Ні | прапор -f | Ні | Ні | Unix-термінал |
PowerShell Select-Object -Unique | Так | прапор -CaseSensitive | Ні | Ні | Windows |
| Розширення VS Code | Так | Залежить | Залежить | Ні | Інсталяція розширення |
| Видалити дублікати онлайн | Так | Перемикач | Перемикач | Ні | Жодного |
| Regex Find & Replace | Так | прапор (?i) | Вручну | Так | Жодного |
Пастка пробілів
Це ловить розробників щоразу: "hello" і " hello " — не той самий рядок. Порівняння рядків за замовчуванням точне. Якщо твої дублікати мають непослідовні пробіли на початку чи в кінці — а це трапляється постійно зі вставленим вмістом, витягами з PDF та експортами з таблиць, — ти проженеш дедуплікацію й усе одно матимеш «дублікати».
Виправлення — спершу обрізати, а тоді дедуплікувати. Інструмент Видалити дублікати робить це чекбоксом. В awk:
awk '{gsub(/^[ \t]+|[ \t]+$/, "")} !seen[$0]++' input.txt > output.txt
gsub(/^[ \t]+|[ \t]+$/, "") зрізає пробіли й табуляції на початку й у кінці кожного рядка перед перевіркою на дублікат — не торкаючись нічого всередині рядка. Це означає, що значення, розділені табами, й поля CSV лишаються цілими. Утім, воно не зловить нерозривні пробіли (U+00A0) чи пробіли нульової ширини (U+200B) — ті переживають стандартне обрізання. Якщо чистиш текст, що прийшов із вставлення з PDF чи копіювання з вебу, спершу прожени його через Виправити пробіли, щоб прибрати невидимі символи, а тоді дедуплікуй.
Глибший погляд на те, чому вставлений текст узагалі приходить забрудненим, — у Як прибрати зайві пробіли з тексту онлайн, де розглянуто проблему витягання з PDF на основі координат і варіанти пробільних символів Unicode, які str.trim() тихо проґавлює.
Коли дублікати рядків — симптом, а не проблема
Якщо ти регулярно дедуплікуєш той самий файл, першопричина майже завжди — баг ідемпотентності вище за течією. Поширені патерни:
- Cron-завдання, що дописує у файл замість перезаписувати його
- Агрегатор логів без
DISTINCTу його SQL-запиті - Стартовий скрипт, що повторно додає конфіг-записи, які вже існують
- Злиття Git, що продублювало контекстні рядки в погано розв'язаному конфлікті
Дедуплікувати вручну — це пластир. Полагодити генератор — це виправлення. Прожени дедуплікацію раз, щоб почистити поточний стан, а тоді простеж назад, чому вхід узагалі продукує повтори.
Інсайт від сеньйора: завжди виводь у новий файл
🍌 Ніколи не запускай дедуплікацію просто на своїх продакшен-файлах
.envчи конфігу застосунку без бекапу. Завжди спрямовуй вивід у новий файл — як у прикладах вище — і прожени швидкийdiff input.txt output.txt, перш ніж замінювати оригінал. Легко випадково згорнути два рядки, що виглядають однаково, але несуть структурно різні значення (як-от два записиDATABASE_URL, що вказують на різні репліки). Спершу diff, заміна — другою.
Сортування після дедуплікації
Щойно дублікати зникли, можеш захотіти відсортувати рядки, що лишилися — корисно для файлів .env, списків імпортів чи словникових файлів, де абеткове впорядкування полегшує читабельність і дифи на код-рев'ю.
Інструмент Сортувати рядки це робить: A→Z, Z→A, найкоротші спершу, найдовші спершу чи випадкове перемішування через Fisher-Yates. Рекомендований порядок завжди — спершу дедуплікувати, потім сортувати, а не навпаки, бо інакше ти подаси відсортований вхід у порівняння, що може повестися не так, як очікуєш.