
Опубліковано: 2026-06-26
Keyword Density: What It Is and How to Calculate It
Keyword density is occurrences ÷ total words × 100. Learn the formula, why the 'ideal percentage' is a myth, and how to check yours free in your browser.
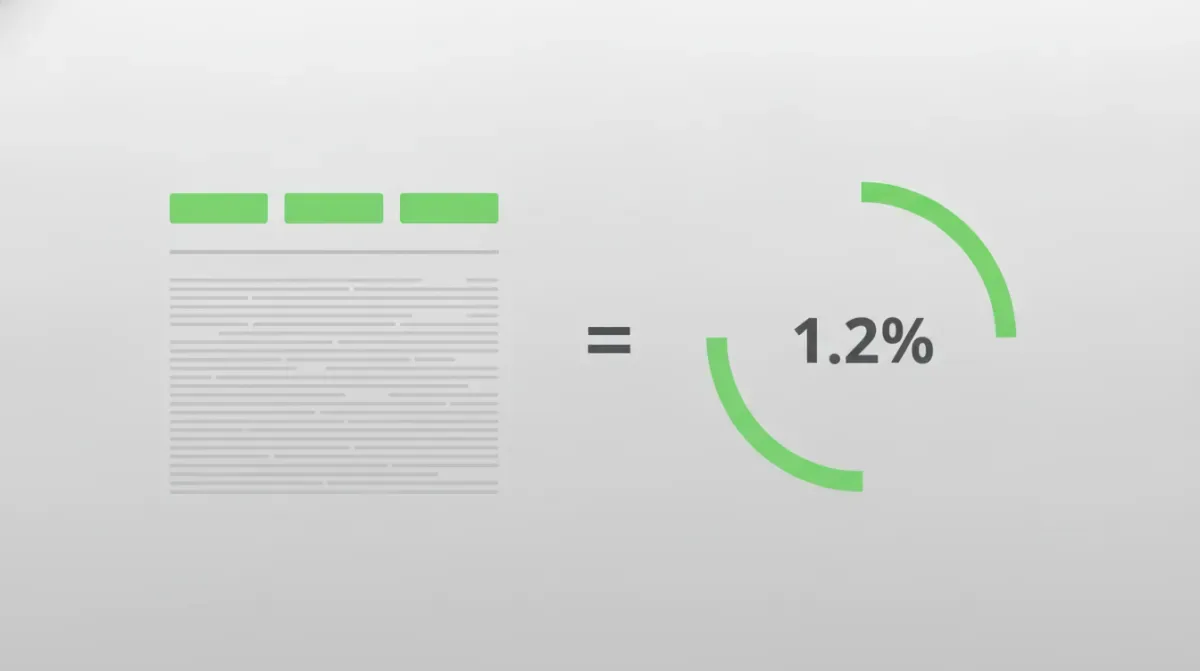
Keyword density is one number: how often a phrase appears, divided by your total word count, times 100. A keyword used 12 times in a 1,000-word article has a density of 1.2%. That's the whole definition — everything else is interpretation.
Here's the part most "ultimate guides" bury: there is no ideal percentage to hit. Google dropped keyword density as a target signal back in 2011. What density is actually good for in 2026 is the opposite of what it was sold as — it's a way to catch a phrase you've accidentally stuffed, not a quota to fill. Below is the formula, the math that trips people up, and how to read the number without fooling yourself.
The Keyword Density Formula
The math is grade-school division. Count the occurrences of your phrase, divide by the total words on the page, multiply by 100.
$$\text{Keyword Density} = \frac{\text{Keyword Occurrences}}{\text{Total Words}} \times 100$$
Run it on a real example — a phrase appearing 12 times in a 1,000-word post:
$$\frac{12 \text{ occurrences}}{1{,}000 \text{ words}} \times 100 = \textbf{1.2%}$$
Simple enough. The trap is the denominator, and it's where two different tools will hand you two different numbers for the same text.
For multi-word phrases, what counts as "total words"? Most checkers — ours included — divide by the total count of single words, not by the number of phrase-slots. So a 2-word phrase that appears 5 times in a 1,000-word document reports as 0.5% (5 ÷ 1,000), not 1.0%. A tool that divides by phrase-slots would tell you something else entirely. Neither is "wrong," but if you compare a number from one tool against a number from another, you're comparing apples to a different fruit. Always check the denominator before you trust a percentage.
The "Ideal Keyword Density" Is a Myth
You'll still find blog posts insisting on a magic range — "aim for 1–2%," "keep it under 2.5%." Treat those numbers the way you'd treat a code comment that says // TODO: fix later (2014). They're relics.
Two things killed the target-density era:
- Panda (2011) started penalizing thin, over-optimized pages, and Google's own John Mueller has said flatly there's no ideal keyword density to optimize for.
- BERT (2019) and the transformer models that followed read meaning, not repetition. The engine understands that "fix a flat tire" and "repair a punctured wheel" are the same topic. Hammering one exact phrase doesn't help it understand you better — it just makes your copy worse.
So flip the mental model. Density isn't a thermostat you set to 1.5%. It's a smoke detector. The only threshold that matters is the ceiling: if one phrase climbs well past what reads naturally, you've got a problem to fix.
| Density of a single phrase | What it usually signals | What to do |
|---|---|---|
| Under 0.5% | Barely present | Fine — only worth boosting if it's genuinely your main topic |
| 0.5%–1.5% | Natural usage | Leave it alone |
| 1.5%–3% | Heavy — borderline | Read it aloud; swap a few instances for synonyms |
| Over 3% | Over-optimized | Cut occurrences — this reads as spam to Google and humans |
This is a reading, not a target. Write for a person first. Then check density to make sure you didn't accidentally lean on one phrase 30 times — which is exactly the kind of unconscious repetition our word frequency analysis guide covers from the editing angle.
Single Words vs. Phrases — Why 2-Grams Win
Single-word density is mostly noise. Of course "marketing" is your most common word in a post about marketing. That tells you nothing actionable.
The signal lives in phrases — 2-grams and 3-grams in NLP terms. "Email marketing automation" sitting at 1.8% is a real, specific signal about what the page is optimized for. That's why our checker defaults to 2-word mode. But phrases create a stop-word headache that most tools handle badly.
The naïve approaches both fail:
- Keep every stop word, and your 2-gram list is just "of the," "in the," "to the" — grammar, not topics.
- Strip any phrase containing a stop word, and you lose real phrases like "rule of thumb" or "state of the art."
Our checker uses a boundary stop-word filter: it drops an n-gram only if its first or last token is a function word, while keeping internal ones. So "of the" disappears, but "rule of thumb" survives intact. Here's the filter deciding on real 3-grams — only the edges are checked:
| Phrase | First word | Last word | Verdict |
|---|---|---|---|
| of the day | of (stop) | day | ❌ Dropped — edge is a stop word |
| end of the | end | the (stop) | ❌ Dropped — edge is a stop word |
| rule of thumb | rule | thumb | ✅ Kept — of sits in the middle |
| point of view | point | view | ✅ Kept — of sits in the middle |
| email marketing automation | automation | ✅ Kept — no stop words at all |
It's the difference between a phrase list you can act on and a wall of prepositions.
How to Check Keyword Density (Free, In Your Browser)
Paste your draft into our Keyword Density Checker — every n-gram is counted in a Web Worker running inside your own tab, so your text never leaves the browser, no upload and no account. Here's the workflow:
- Paste your content into the box. The tool tokenizes with
Intl.Segmenterand counts phrases as you type, debounced so even a 100,000-word manuscript won't freeze the page. - Pick a phrase length. Start with the default 2-word view for topic signals; switch to 1-word to spot a single over-used term, or 3-word to audit exact-match long-tail phrases.
- Keep "Exclude common words" on. That's the boundary stop-word filter — it clears the prepositional clutter so your real phrases rank to the top.
- Sort by density and read the top of the list. Anything that looks forced gets fixed. Export the table to CSV if you're auditing a batch of pages.
When you find a phrase you've over-used, don't delete blindly — vary it. Our Find & Replace tool (with regex support) lets you swap a stuffed keyword for synonyms across the whole document in one pass. And if trimming the over-optimized section pushes you over a length budget, the techniques in how to reduce word count cut the bloat without gutting meaning. For the raw total-word baseline every density calculation depends on, the homepage Word Counter is the fastest check.
Keyword Density vs. Word Frequency
These two get conflated constantly. They share the arithmetic and split on intent.
| Keyword Density | Word Frequency | |
|---|---|---|
| Goal | SEO: is a target phrase over- or under-used? | Editing: which words do I repeat unconsciously? |
| Unit | Phrase (1–3 words) as % of total | Single word, count + % |
| You want the number to… | Stay under a ceiling | Come down (cut the tics) |
| Tool | Keyword Density Checker | Word Frequency Counter |
Use density when you're optimizing a page and want to confirm you didn't tip into spam. Use frequency when you're self-editing prose and hunting for the verb you've leaned on six times in two paragraphs. Same percentages, opposite direction of travel.
The honest takeaway: keyword density is a 2008 metric that survived into 2026 as a diagnostic, not a strategy. Don't chase a percentage. Write the page for the reader, run a 60-second density check to catch accidental stuffing, fix the outliers, ship it.